.webp)




Analyse de donnees
Le stockage de données, méthodes et outils
Découvrez comment stocker de grandes quantités de données, les méthodes, les outils, les types de bases de données, le Data Lake ou encore le Data Management.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Téléchargez le programme de nos formations
Téléchargez le rapport d’insertion 2025


À l'ère du numérique, la gestion optimale des données informatiques recueillies est essentielle au succès d'une activité. À cet effet, on entend d'ailleurs parler de plus en plus souvent du Business Intelligence ou Informatique Décisionnelle. Il s'agit de l'ensemble des infrastructures, applications et techniques qui concernent la collecte, le traitement et l'analyse d'informations numériques à des fins d'optimisation des performances d'une entité. Plus précisément, on peut produire des graphiques statistiques, des tableaux de bord, des indices KPI ou encore des rapports qui permettent d'améliorer les prises de décisions commerciales ou de fonctionnement interne.
Dans cette chaîne de traitement des données numériques, la bonne réalisation du processus ETL (Extract-Transform-Load) est indispensable pour garantir une meilleure suite des opérations. Pour tout technicien chargé de l'ETL, une formation Data engineering de grande qualité est nécessaire pour la réalisation en bonne et due forme des procédés informatiques adéquats. Comment justifier la pertinence du processus ETL ? Quels sont les tenants et aboutissants de ce processus informatique ?
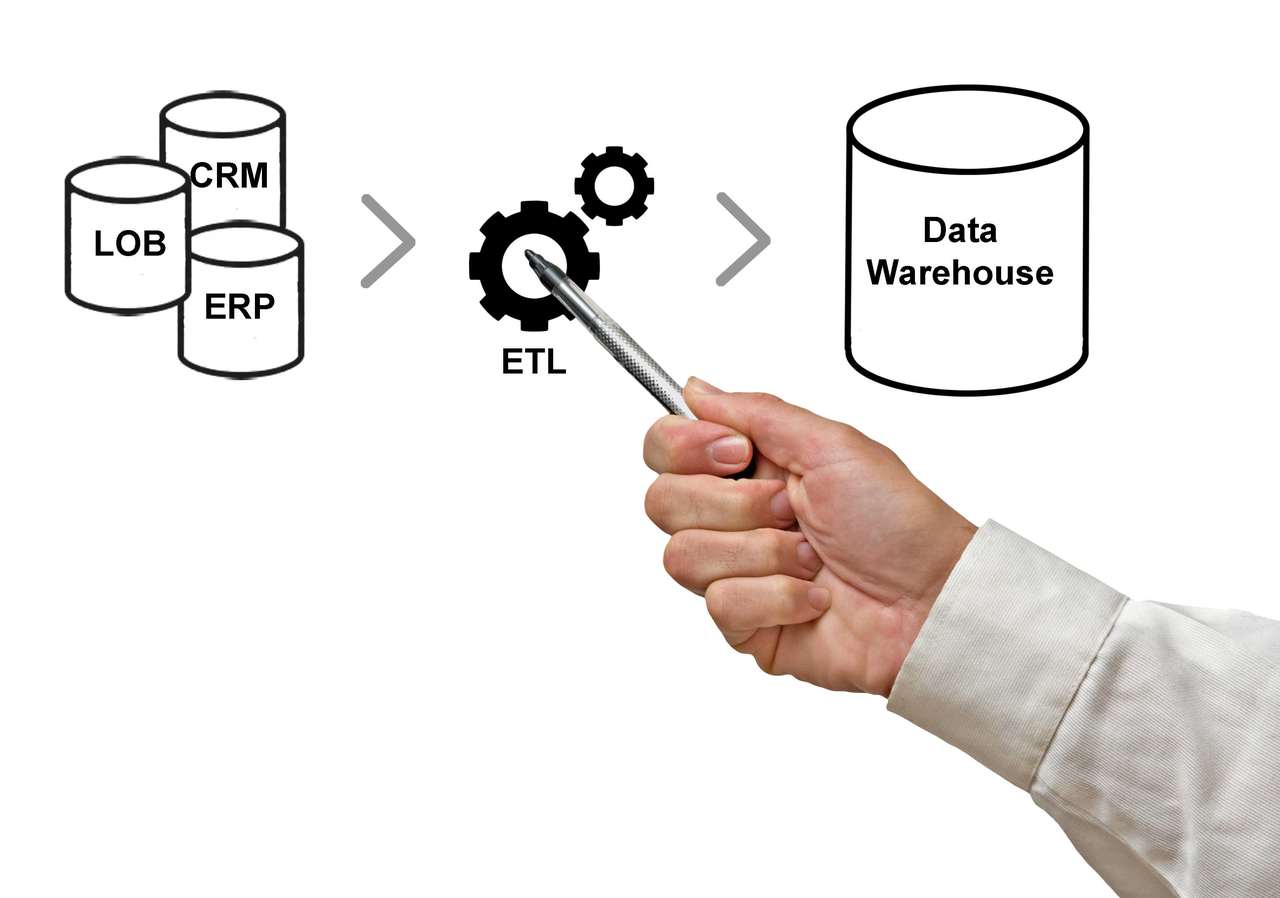
Ce processus fait inéluctablement partie des connaissances à maîtriser quand on est un Data Engineer. Le Data engineering regroupe en effet les techniques informatiques permettant de construire, de développer et de maintenir les différentes architectures d'acquisition, de stockage et de gestion des données numériques. Le Data Engineer se charge de mettre en place un pipeline de données efficace au vu des objectifs de fonctionnement de l'entreprise, ce qui facilitera le travail pour le Data Scientist. Une fois que les données ont été produites et rangées, le Data Scientist aura seulement à détecter les tendances générales qui proviennent de l'analyse de données grâce à des algorithmes spécifiques. Le rôle du data engineering est donc primordial pour optimiser les tâches des autres spécialistes de la Data, car il fournit le socle de travail : des bases de données savamment construites et maintenues.
Aujourd'hui, les entreprises enregistrent de gros volumes de données à travers la mise en place de CRM, ERP, des applications de ventes, des sites web, des questionnaires de panel consommateurs ou encore des bases Excel.
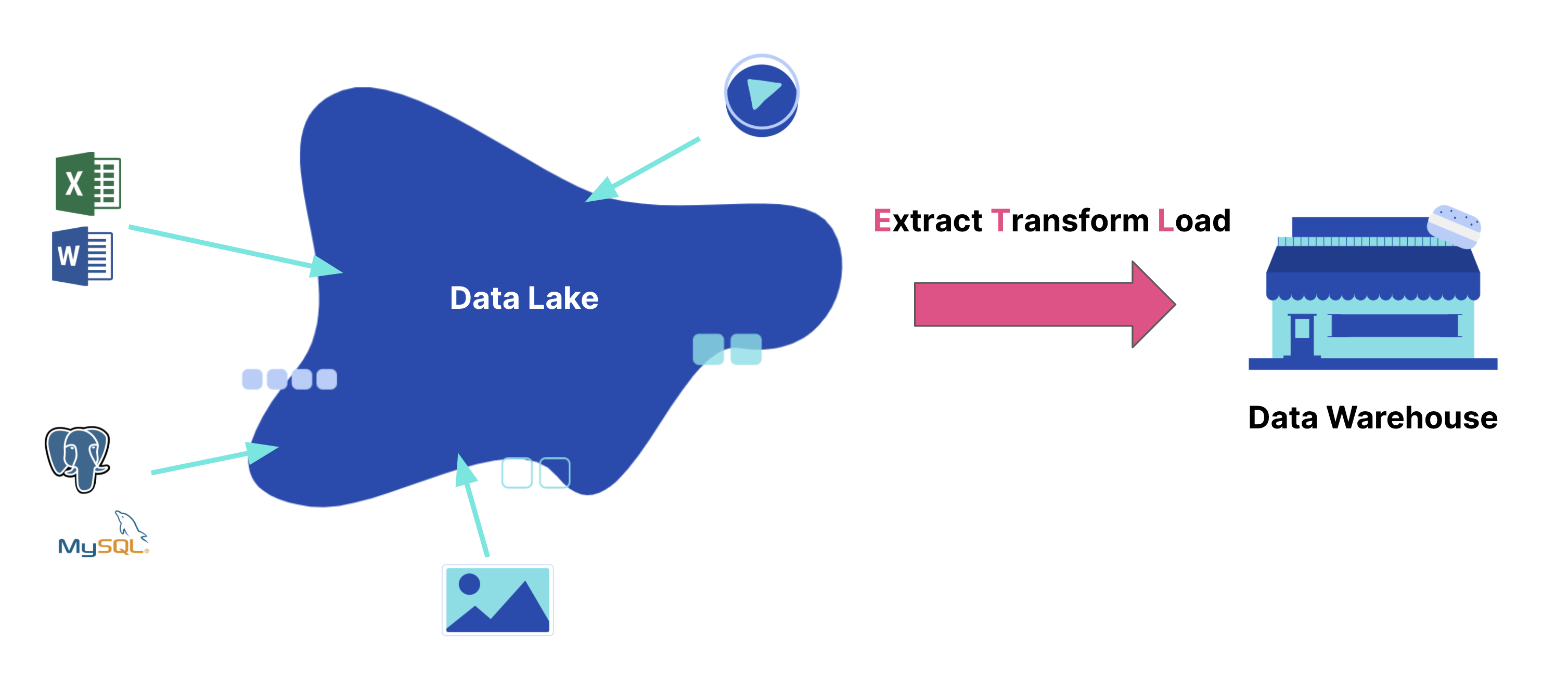
Pour centraliser toutes ces informations au niveau d'une base de référence, l'ingénieur des données a le choix entre un Data Warehouse et un Data Lake. Le Data Lake séduit aujourd'hui certaines organisations par le coût relativement réduit de stockage, des temps de processing plus courts, la facilité accrue de modification et d'analyse des données stockées et aussi le grand volume de stockage offert. Ce gigantesque rassemblement d'informations numériques structurées et non structurées n'est principalement manipulable que par les Data Scientists qui ne représentent généralement qu'un effectif très réduit du personnel d'une organisation. L'architecture du Data Lake facilite en effet les analyses Data avancées concernant la modélisation prédictive, le Machine Learning ou encore la modélisation prescriptive grâce à l'intelligence artificielle.
Cependant, la plupart des entreprises actuelles disposent dans leur rang d'un nombre élevé d'agents opérationnels possédant des cœurs de métier bien spécifiques. À l'ère du numérique, ces derniers éprouvent aussi un besoin crucial d'accéder facilement aux données virtuelles précisément liées à leurs activités spécifiques. Il en va de l'amélioration de leurs méthodes de travail. En ce sens, un Data Warehouse connecté aux différentes sources de données transactionnelles par un processus ETL s'avère idéal. Ce type de stockage de données présente uniquement des informations structurées et facilement compréhensibles pour chaque utilisateur opérationnel de l'organisation. En d'autres termes, qu'il s'agisse d'une équipe de marketing, du service comptable ou de l'équipe de techniciens sur terrain, la Data Warehouse permet à chaque acteur de strictement accéder à des données dont l'usage final est déjà défini (les métriques de performance en l'occurrence).
En plus de la maitrise des langages de programmation spécialisés comme Python, C+ ou SQL et des systèmes d'exploitation ( Linux, UNIX, Solaris, Windows…), le Data Engineer doit donc avoir une parfaite connaissance des outils ETL. Il peut alors configurer des Datas Warehouses performants et orientés métier pour optimiser le travail des divers spécialistes de l'entreprise qui ne sont pas habitués au langage informatique. Par ce moyen, il devient un élément clé de l'évolution de son l'organisation.

N'importe quelle personne suffisamment motivée peut devenir un Data Engineer en suivant une formation de type bootcamp. Peu importe sa précédente occupation professionnelle, ce genre de formation favorisera par exemple la réussite d'un projet de reconversion professionnelle. Choisir une formation Data Engineering permet de bien maîtriser les différents outils d'intégration, de consolidation, d'organisation et de gestion des infrastructures data d'une entreprise. Tout en s'adaptant au rythme de l'apprenant, la formation Data Engineer lui permet d'acquérir rapidement les différentes compétences requises en s'alignant sur les besoins réels des entreprises. Elle apprend à structurer toutes les données de la société afin de les rendre accessibles à l'ensemble des départements grâce au processus ETL. Pour cela, l'apprenant est formé en ce qui concerne la collecte de la donnée, son pré-processing et son stockage dans une Data Warehouse. De plus, des experts chevronnés lui montreront comment automatiser les services d'AWS (RedShift, Athena, Dynamo DB…) avec le programme Airflow.
La formation Data Engineering concerne également le codage en Scala, la gestion des architectures de données grâce à Spark et la maitrise des compétences DevOps pour la standardisation d'un environnement de code et le scalage d'une application. Une formation reconnue par l'État est éligible au CPF. Pour réellement devenir autonome en Data, il est possible de bénéficier de formations spécialisées online additionnelles sur la plateforme Julie. Un environnement de code est accessible pour faciliter l'apprentissage. À tout moment, grâce à une vaste communauté de data savvy, les apprenants peuvent se faire aider par l'équipe pédagogique ou d'autres apprenants en cas de problèmes de codage. La formation Data Engineer présente donc plusieurs avantages pour toute personne désirant maîtriser la gestion de bases de données via le processus ETL.
À travers la construction d'un entrepôt de données, il permet d'intégrer et d'avoir une vue précise des principales informations numériques relatives à chaque service d'une organisation. Lorsqu'il s'est correctement réalisé, l'ETL brise les silos de données et rend l'information accessible à tous les actifs de l'entreprise. Toute chose qui optimise le Business Intelligence, permettant ainsi de prendre des décisions commerciales plus avisées. Il sert également à transférer les données d'une application à une autre. En raison des progrès réalisés dans le domaine du Big Data, des interactions sur réseau social et de l'Internet des objets, les dispositifs ETL ont également dû faire évoluer leur compatibilité avec les différentes sources de données. On les utilise par exemple pour faire migrer les données d'un ancien système vers un nouveau système qui exige des formats de données plus avancés.
Cet outil aide parfois à la migration des applications on-premise vers les architectures basées sur le cloud. Par ailleurs, l'ETL peut permettre de cartographier les données d'activité au sein d'une organisation. En supprimant les incohérences au niveau des informations récoltées, il permet indirectement d'améliorer la sécurité et la qualité des bases de données. En somme, l'Extract-Transform-Load permet au Data Engineer de résoudre efficacement la majorité des problèmes liés à la collecte, au traitement et au transfert des informations numériques au sein d'une organisation.

Il s'agit d'un processus informatique qui consiste à extraire des données brutes d'une multitude de sources, à les structurer et enfin à les déposer dans un environnement de stockage adapté, notamment un Warehouse. On distingue donc trois étapes principales : l'extraction, la transformation et le chargement des données.
Cette première phase correspond à l'identification des sources d'information et au prélèvement des données brutes au niveau des sources identifiées. Généralement, les ressources concernées sont les logs d'activité, les évènements de sécurité, les performances des applications cloud, les logiciels professionnels, les feuilles de calcul Excel, les informations sur site web… En fonction des capacités du dispositif de traitement et du volume d'informations numériques à extraire (d'une centaine de kilo-octets à plusieurs giga-octets), cette opération peut durer quelques heures ou quelques jours.
Souvent, le Data Engineer doit à cette étape introduire de la cohérence au sein des données. Pour cela, il doit réorganiser les données suivant leur taille et leur date de création. Ces données extraites sont ensuite transportées vers un système de traitement spécial pour subir les transformations nécessaires.
L'ingénieur Data doit désormais convertir, reformater et nettoyer les données brutes agrégées. Il s'agit d'appliquer aux données un ensemble pertinent de fonctions logicielles ETL pour faire correspondre les informations extraites aux exigences structurelles de la base cible. Les données transformées doivent également permettre de répondre efficacement à des besoins spécifiques de l'organisation. Pour préparer les données à futur chargement, certaines règles internes destinées à garantir la qualité des informations de la base finale sont appliquées :
La standardisation permet au Data Engineer de définir au départ les types de données à traiter, les formats acceptés, les modes adéquats de stockage de même que d'autres modalités d'intégration Data qu'il juge nécessaire. Cette première règle élimine au premier abord une grande partie de fichiers non pertinents. En ce qui concerne la déduplication, le processus ETL transmet à l'ingénieur tous les rapports relatifs aux problématiques de doublon. Automatiquement, il se charge également d'éliminer les données redondantes. La norme de vérification suppose une automatisation du contrôle des données similaires pour informer le professionnel sur les dysfonctionnements système ou données.
Elle permet aussi de supprimer les informations inutilisables qui sont encore présentes après l'application des règles précédentes. Enfin, la fonction de tri du processus ETL rassemble les données par catégorie. Images, audios, vidéos, mail, etc. Tout est convenablement classé pour augmenter l'efficacité des requêtes qui seront lancées. Les quatre règles décrites sont celles qui sont généralement exécutées dans le cadre de ce processus. Suivant les besoins spécifiques de l'organisation et les utilisateurs finaux, l'on peut décider d'ajouter certaines règles afin de personnaliser au mieux les Warehouses. Une fois que les données ont été correctement structurées, elles peuvent désormais être chargées dans leur emplacement final.
Deux méthodes principales sont utilisées pour déposer les données extraites et transformées dans l'entrepôt numérique cible. Il s'agit du chargement intégral et du chargement incrémental. Le chargement intégral implique le déversement de l'entièreté des données lors de la seule et unique fois que la source est connectée à la Warehouse. Cette méthode est efficace lorsque l'on est sûr que tous les ensembles d'informations ne contiennent pas d'erreurs. La charge incrémentale basée sur l'insertion SQL (avec un contrôle de l'intégrité des informations à chaque enregistrement) permet l'entreposage des données à intervalles réguliers de temps. On distingue ici les incréments de lots qui conviennent au transfert de gros volumes de données et les incréments de flux qui sont liés aux faibles volumes de données.

La réalisation de l'ETL nécessite l'utilisation d'outils logiciels spécialement conçus à cet effet. Chaque technologie dispose de fonctionnalités spécifiques plus ou moins orientées vers la synchronisation des données entre systèmes ou sur leur transformation proprement dite. Aujourd'hui, les technologies ETL basées sur le cloud comme Aloma ou AWS sont celles que préconisent la majorité des entreprises. L'enregistrement des données sur un serveur distant dans le cloud apporte en effet plus de flexibilité au propriétaire, peu importe sa localisation géographique. Le traitement de données est possible en temps réel et les transferts sont extrêmement rapides.
Les technologies sur cloud sont également moins coûteuses que celles on-premise proposées par Microsoft ou IBM par exemple. Les solutions on-premise sont assez complexes à manipuler et maintenir, à moins de trouver un ingénieur Data très compétent pour réaliser les interventions nécessaires. Nous avons enfin les outils ETL Open Source comme Apache Airflow ou Talend Open Studio qui malgré leur gratuité offrent des performances honorables en matière d'intégration de données. À côté des outils d'intégration, l'ingénieur Data pourra également compter sur les systèmes de bases de données relationnelles comme Microsoft SQL Server ou MySQL. Pour connecter différents serveurs, REST, ODBC, FTP ou SOAP sont des solutions très utiles.
Le processus ETL est essentiel pour la constitution de bases de données efficaces et orientées métier en entreprise. Il va sans dire que tout bon Data Engineer doit nécessairement maîtriser ce procédé informatique pour participer activement à la performance de son organisation. Au vu de l'évolution croissante de la volumétrie des données en entreprise, il ne fait aucun doute que le poste d'ingénieur Data sera encore plus recherché sur le marché de l'emploi dans les années à venir. Quiconque envisage une carrière dans ce domaine a tout intérêt à se tourner vers une formation Data qualifiante.
Si vous souhaitez acquérir les compétences et maîtriser tout le pipeline Data, n'hésitez pas à regarder notre formation Data Scientist.